Results
The results were RIM-weighted back to the quota targets to correct for over- and under fills, with interlocking added. Due to the quotas, the weighting required was minimal, with a design effect of 1.04 (or 96 per cent efficiency). Below are some of the key numbers, compared with the actual results or best available estimates.
2017 general election and 2016 EU referendum:
| Unweighted | Weighted | Result | |
| CON | 41.9 | 42.3 | 43.5 |
| LAB | 39.8 | 39.1 | 41.0 |
| LD | 6.8 | 7.0 | 7.6 |
| SNP | 4.0 | 4.3 | 3.1 |
| UKIP | 3.1 | 3.1 | 1.9 |
| GRN | 2.8 | 2.5 | 1.7 |
| Others | 1.7 | 1.6 | 1.2 |
| Remain | 47.8 | 47.5 | 48.1 |
| Leave | 52.2 | 52.5 | 51.9 |
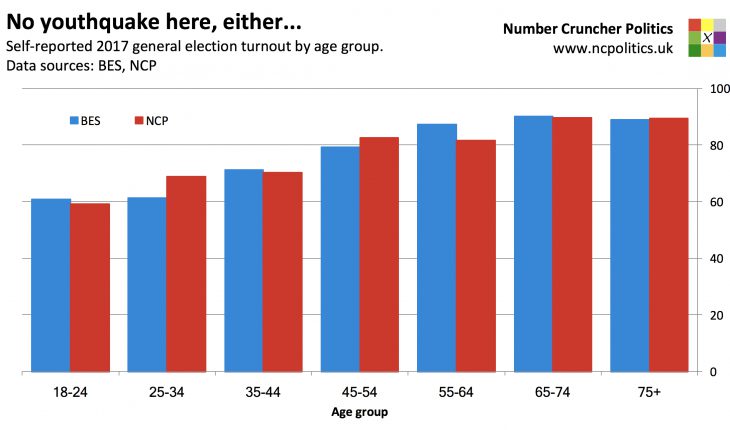
2017 turnout by age:
| Unweighted | Weighted | BES* | |
| 18-24 | 61.0 | 59.1 | 60.8 |
| 25-44 | 69.2 | 69.6 | 66.2 |
| 45-64 | 82.2 | 82.2 | 82.9 |
| 65+ | 89.8 | 89.5 | 89.6 |
| All ages | 77.8 | 77.5 | 77.0 |
*using demographic weights (wt_demog)
The raw numbers, without any weighting applied, show that the sample recalls voting Conservative over Labour by around 2 points in 2017 – very close to the Tories’ actual popular vote margin of 2.5 points. It remembers voting about 52-48 to leave the EU, again in line with the 2016 result.
What about turnout? Well, it’s well known that people tend to recall voting when they in fact did not, so from a sample quality perspective, it doesn’t make sense to compare it to the actual turnout. For reference, that was 69 per cent of the electoral roll or 68 per cent of the voting eligible population (the latter being the measure used here).
Using respondents’ self-reported turnout, the gold standard British Election Study (BES) found that 77 per cent of eligible voters claimed to have voted, very similar to the 77.5 per cent in our poll. But the really interesting similarity is in the pattern of turnout by age. Only 59 per cent of 18-24 year olds said they’d voted, slightly below the BES estimate, with the two surveys displaying very similar patterns across age brackets. (Which, incidentally, is yet another piece of evidence that there was no youthquake).

The poll isn’t perfect – the proportions recalling voting for two main parties are each a point or two below the result, with the smaller parties doing a bit better. Unlike “two-stage” voting intention questions, our recalled 2017 vote question prompted for all parties together, which in retrospect may have been a mistake.
And on political attention, measured on an 11-point scale from zero (pay no attention) to 10 (pay a great deal of attention), we sampled slightly too many people in the most engaged buckets 9 and 10 and slightly too few in the less engaged buckets 2-4. This is something we’ll look into with a view to improving, and it may well explain the slight (0.5 point) turnout overestimate relative to the BES. Importantly however, the sums of the 5-8 range (where most voters are) and the 0-2 range (which contains almost half of non-voters) were spot on, and the errors mentioned above are still a lot smaller than usual.

Conclusions and next steps
On sample representativeness, we may well have made some progress. It seems that if you look in the right places, it may, after all, be possible to get hold of politically disinterested people, without spending months and hundreds of thousands of pounds on an address-based probability survey. While interesting results always warrant scepticism, these initial findings are promising.
Quite a lot of analysis will now follow, to better understand the data, the process and to see whether the work can be sped up without compromising accuracy, or otherwise improved.
Feedback is welcome. In line with polling industry practice, we will be publishing computer tables on this website after the release of poll results.
{kind=link}