When James Kanagasooriam and I published Polls apart late on Tuesday, we made it clear that we wanted to prompt a debate. We seem to have succeeded, and we appreciate all of the discussion, both positive and critical.
There have been some excellent writeups, including from the BBC, FT, Guardian, Times, Independent and Bloomberg. In general the response from pollsters has been positive, and sources suggest that a number of them have begun experiments in response. However there has also been criticism, and it’s that that I’ll address here.
It’s important to not to let the row over who’s right obscure the finding that will matter long after the 23rd of June – that the attitudinal composition of samples matters, and can vary even within weighting cells. And although (given a decent turnout) the referendum vote will itself be a useful weighting variable thereafter, the broader concept will matter far beyond the referendum – and beyond our shores.
John Curtice noted that in his post. Other write-ups came from Anthony Wells, Harry Carr, Mike Smithson and Stephan Shakespeare. We did not single online polling out for criticism, and certainly not an individual polling company. Different polling modes have their respective strengths and weaknesses, and closer in one situation does not equal inherent, across-the-board superiority.
To be clear, I have no problem with people criticising my work (or in this case, work I did jointly with Populus). We would have started a pretty meaningless debate if everyone simply agreed. Some of the comments do highlight genuine risks to the thesis.
However it appears that some of the key points have been misunderstood. We did purge a significant amount of technical detail that wouldn’t be of interest to non-pollwatchers, but which is relevant to more detailed discussions about methodology. There will also inevitably be aspects of the analysis that we could have done a better job of explaining.
But in other cases, it appears that some critics of the paper might not have read it thoroughly. Some may have evaluated our thesis based on media coverage, which although fair and accurate is necessarily a discussion of the salient points appropriate to a wide audience, not a full technical account of the paper with all of detail and caveats.
This post, then, is aimed at addressing the points raised, and is my personal view.
What we do know about don’t knows
Our argument was not about the outright level of undecided voters, and there’s a good reason for this – it’s only a small subsection that we’re interested in – specifically those that seem to be answering differently depending on how the question is presented.
John Curtice’s point about squeezing is a concern – it appears that prompting for don’t knows and then squeezing them has a slightly different effect to simply not prompting (as was the procedure in our split test). This is an interesting puzzle, but we think it more likely that adding a third option that is not on the ballot paper – which is essentially an artefact of the self-completing nature of online polls – creates additional uncertainty among a group of voters that seem to lean quite strongly lean one way.
The point is not that a poll that produces fewer don’t knows is inherently better, but more that pushing people with a clear leaning away from that answer risks giving a misleading picture.
With respect to the online polls by ORB, which present a “hard” forced choice, the way to be certain of the effect of this would be a genuine apples-to-apples comparison, by prompting for a don’t know option while holding everything else constant – something which ORB has not yet done on a published poll. It is quite possible that doing so would show a lead for Leave.
The evidence against the BES seems misleading
I’m not accusing anyone of misleading deliberately. Sometimes numbers appear to show one thing, but the underlying pattern shows something else. On the face of it, the BES (and BSA) appeared to get the UKIP vote share too low. But in the weeks immediately after the election, the reported UKIP vote share was not too low… In fact at the very start, it was too high, even after adjusting for the parts of the country being sampled and the contactability of the respondents. In other words, people appear to be forgetting how they voted.
This is not just what the data shows, but entirely consistent with theory and past research. I suspect that most people reading this will be particularly interested in politics and as such will have no trouble remembering whether or how they voted last May, or indeed in many elections beforehand. But among the wider population, people don’t always accurately remember what they did in the polling booth (or even if they made it there). Most of these errors cancel each other out. But at the margin, people usually over-remember voting for Labour and the Tories and under-remember voting for the smaller parties. This is what appears to have happened by the end of the months-long fieldwork period.
Both the BES and BSA had the Conservatives and Labour too high (with the gap between them about right). Aside from UKIP, the BES had also had the Lib Dems and Greens too low, while the BSA had the Lib Dems too low and the Greens about right. If we look at Lab+Con and UKIP+Lib+Grn cumulative recalled votes over time, the trend is pretty clear.

So we see no reason to think that the BES sample was unrepresentative and, for the avoidance of doubt, it doesn’t look like an interviewer effect either. It looks as though a representative sample of people were (to the best of their recollection) telling the truth. The people in it did actually vote for UKIP well within the margin of error of the 12.9% of the mainland vote that UKIP got.
This is not to rule out interviewer effects elsewhere (I’ll address later), but it does not support the idea of shy UKIPpers.
Ironically, this problem actually highlights what it normally an advantage of online panels. Instead of asking people to remember who they voted for up to 5 years prior, online pollsters can easily return to the same people over time and, for example, weight to their party ID or past vote that was declared at the time of the previous election. This can be a significant advantage in normal voting intention polling.
I’m not saying that social research is a substitute for opinion polls. It is too expensive and slow for most of the applications of polls. But it is an extremely useful compliment and its use for things like calibration ought to be explored further.
We did NOT ignore interviewer effects
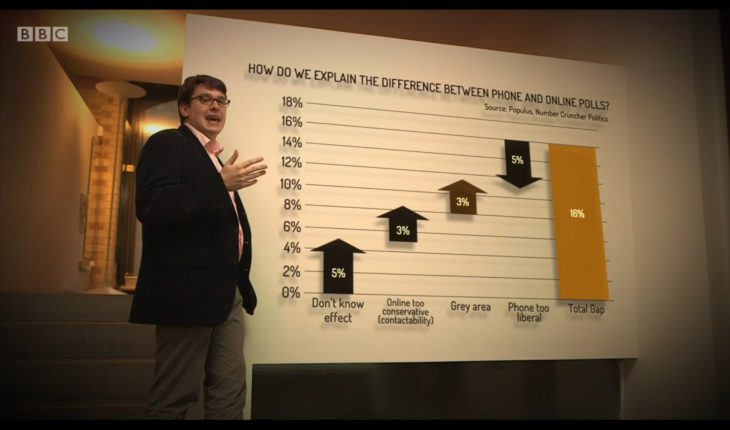
Contactability bias and interviewer effects are two separate issues, but I’ll take them together. Essentially we have three sets of answers – phone is more liberal and Europhile, online is more conservative and Eurosceptic, and the BES is between the two.
For the phone polls, the issue is relatively straightforward. Both phone and face-to-face polls involve live interviewers, so we can be pretty confident that it’s safe to reweight based on attitudinal variables, even though there might be a small modal difference in interviewer effects. Doing so essentially brings the phone polls into line with the BES on EURef too.
What about online? A number of people assumed that we simply weighted the online results to match the answers to the sensitive questions in the BES. We did not. In fact we were actually rather cautious.
We knew that significant part of the gap between online and the BES would be due to interviewer effects. But it also seemed pretty clear from the sorts of patterns we were observing in the data that there was something more to it – that they are talking to different people. To give an example, the following tables show the pseudo r-squared we got from our logistic regression models for remain and leave, by sample. It is very clear clear that the online sample does not have the sort of randomness that other modes produce. This does not necessarily mean the online is less accurate than phone polling – there could be other biases that affect phone polls, as we believe there are. But it does indicate a particular problem with online samples that relates to who is in the sample (and not just who is not).
| Online | Phone | BES face to face | |
| Remain | 0.1854 | 0.1313 | 0.1345 |
| Leave | 0.2035 | 0.1680 | 0.1729 |
Our logic therefore was to consider the component of the gap on the attitudinal questions that couldn’t be an interviewer effect, and use that to adjust what was in the online polls.
The alternative to taking the approach we did would be to assume that the entire gap between gold standard and online is due to interviewer effects, as some doubtless will. But since poll samples (whether phone or online) are still not perfect, it doesn’t seem sensible to assume this. Indeed as several have said in their reactions, it is probably a mixture of sample and modal effects – this is exactly how we’ve treated it, so the question ought to be whether we’ve struck the right balance.
As such, the reweighting method assumed that ALL of the difference between the sensitive questions online and face to face, over and above the contactability element, was an interviewer effect.
We accept that the effect of diferential contactability could well vary between modes (though the diffference could be in either direction). But it seems perfectly logical that differential availability is at least related to the people themselves. People that simply have busy lives, or are uninterested in taking a survey for a nominal fee, will be busy or uninterested however you approach them. Evidence we gathered from all three modes seems to support that.
Anthony Wells sounded less certain about this issue in his writeup, given that on the EU referendum it appears to point in the opposite direction to the voting intention. It also looked like that to us at first glance. But on closer inspection, it isn’t quite the opposite direction – it is more at right angles. This means that Tories and social liberals are harder to get hold of – and socially liberal Tories especially so. We didn’t just guess that the same sort of people would be missing from online polls and early cuts of the BES – we actually looked at the people involved.
|
BES online panel
|
BES face-to-face (1st calls) |
BES face-to-face (all calls) |
||||
| 2015 vote | Stay | Leave | Stay | Leave | Stay | Leave |
| Conservative | 35.3% | 44.0% | 42.9% | 39.3% | 47.8% | 36.3% |
| Labour | 62.5% | 21.7% | 62.5% | 24.4% | 62.8% | 22.7% |
| Lib Dem | 68.4% | 16.2% | 73.1% | 19.7% | 70.6% | 13.2% |
| UKIP | 5.1% | 88.7% | 9.4% | 88.1% | 11.3% | 81.7% |
| Others | 67.8% | 19.3% | 75.0% | 11.0% | 68.8% | 17.6% |
| Non-voters | 37.9% | 32.6% | 39.9% | 29.9% | 47.0% | 30.3% |
| Total | 44.9% | 38.0% | 47.2% | 36.0% | 50.9% | 32.8% |
| Source: British Election Study post election and cross-sectional waves. Post-election wave is reweighted to 2015 vote instead of 2010. | ||||||
But we have certainly not assumed that the problems in YouGov’s panel that were present (as with other pollsters) last year were still present. I’m not really sure what could have given that impression. To reiterate, this was an investigation of modal differences between phone and online polls, not house effects between individual pollsters. It might be the case that YouGov’s changes give them an advantage over other online pollsters, in which case well done YouGov, but that wasn’t what we were testing. This was a study of modal differences, not house effects. And a significant part of that was the separate set of biases in various polls that is different to what occurred last year.
John Curtice points out that on some questions phone is slightly further from the BES than online. But because the correlations between attitudinal variables and EUref vote is lower in in the former, adjusting for it has less of an impact (see the logistic regression tables in the appendix).
Concluding thoughts
Most of all, we are talking about probabilities. We are not claiming certainty. Rather we have accounted for the difference between phone and online polls and presented our assessment – and the reasoning behind it – of where we think the most likely scenario lies, within a range of possible scenarios. It could be wrong in either direction, but taking all of the evidence into account, this is the one we view as the most likely, as of the fieldwork dates.
Harry Carr described our analysis as “defensible but controversial”. That is fine by us. When I said I thought the general election polls were wrong and that the Conservatives would win by at least 6 points, that prompted a storm. When I said I thought YouGov’s Labour leadership polls were probably right and that Jeremy Corbyn really was well ahead, that raised a few eyebrows. Not to mention that many major innovations in polling (or other fields) were controversial at the time.
Controversial does not equal wrong. I note all the points raised, but stand by the analysis.


{kind=link}